Topic How to find q 1: Finding Q1 (the lower quartile) is an essential step in analyzing data sets. By using the formula (N+1)x(1/4), you can easily calculate this value. Q1 represents the data point that separates the lower 25% of the dataset from the remaining values. Understanding Q1 helps identify the spread and distribution of data, providing valuable insights for statistical analysis and decision-making. With this knowledge, you can confidently interpret data and make informed choices based on accurate information.
Table of Content
- How to find q1 in statistics?
- What is the definition of Quartile 1 (Q1) and how is it calculated?
- How can one find the value of Q1 using the data set provided?
- YOUTUBE: Finding Q1, Q3, and IQR for Interquartile Range
- What is the significance of Quartile 1 in statistical analysis?
- Can you explain the steps involved in finding Q1?
- Is there a specific formula to calculate the lower quartile (Q1)?
- Are there any alternative methods to find Q1 apart from the one mentioned in the search results?
- How does the value of Q1 help in understanding a data set or distribution?
- Are there any limitations or assumptions while using Q1 for analysis?
- Can you provide examples or practical scenarios where finding Q1 is important and useful?
How to find q1 in statistics?
To find Q1 (the first quartile) in statistics, you can follow these steps:
Step 1: Organize your data in ascending order, from smallest to largest.
Step 2: Determine the position of Q1. It is the median of the lower half of the data set. To calculate the position, use the formula (n+1)/4, where n is the total number of data points.
Step 3: If the position calculated in Step 2 is a whole number, simply take the data value at that position as Q1.
Step 4: If the position calculated in Step 2 is not a whole number, round it down to the nearest whole number, and then find the data value at that position. This value represents Q1.
Step 5: Q1 is the value you found in Step 3 or Step 4.
For example, let\'s say you have the data set: 2, 5, 7, 9, 11, 15, 16, 20, 22, 25.
Step 1: The data set is already in ascending order.
Step 2: (10+1)/4 = 11/4 = 2.75. Since this is not a whole number, we move to Step 4.
Step 3: We round down 2.75 to the nearest whole number, which gives us 2.
Step 4: Q1 is the data value at position 2, which is 5.
Therefore, Q1 for this data set is 5.
Remember that Q1 represents the point below which 25% of the data set lies.

READ MORE:
What is the definition of Quartile 1 (Q1) and how is it calculated?
Quartile 1 (Q1) is a statistical measure that represents the value below which a quarter of the dataset falls. In simpler terms, it is the 25th percentile. To calculate Q1, follow these steps:
1. Arrange the dataset in ascending order from smallest to largest.
2. Find the position of Q1 within the dataset. To do this, multiply the total number of data points (N) by 1/4 (or 0.25). If the result is a whole number, this will be the position of Q1. If the result is not a whole number, round it down to the nearest whole number. This will be the position of Q1.
3. If the position of Q1 falls on a whole number, take the value at that position directly in the dataset. This value represents Q1.
4. If the position of Q1 does not fall on a whole number, take the two closest whole numbers on either side of the position. Let\'s call these numbers N1 and N2, with N1 being the smaller one and N2 being the larger one. Calculate the weighted average of N1 and N2 to find Q1.
- Calculate the fractional part of the position of Q1. Subtract the rounded down position from the actual position of Q1. Let\'s call this fractional part F.
- Q1 = (1 - F) * N1 + F * N2. This formula calculates the weighted average by multiplying (1 - F) with N1 and F with N2, then adding the two together.
This process will give you the value of Q1, which represents the value below which a quarter of the dataset falls.
How can one find the value of Q1 using the data set provided?
To find the value of Q1 (the first quartile) using the provided data set, follow these steps:
Step 1: Arrange the data in ascending order, from lowest to highest.
Step 2: Determine the position of Q1 in the ordered data set. Q1 represents the value below which the lowest 25% of the data lies.
Step 3: Calculate the position of Q1 using the formula (N + 1) Ã (1/4), where N is the total number of data points in the set. This formula gives you the rank of the value representing Q1.
Step 4: If the resulting rank is a whole number (integer), the value of Q1 is the corresponding data point. For example, if the rank is 5, the value of Q1 would be the fifth data point in the ordered set.
Step 5: If the resulting rank is a decimal number, it represents a position between two data points. In this case, take the average of the two data points that surround the calculated rank. For example, if the rank is 6.5, the value of Q1 would be the average of the sixth and seventh data points.
It\'s important to note that Q1 is not always exactly at a given data point, especially with small data sets or if the calculated rank falls between two numbers.
Finding Q1, Q3, and IQR for Interquartile Range
Discover the fascinating world of statistics with an in-depth exploration of the Interquartile Range. This essential statistical measure helps us understand the spread of data, and our video breaks down the concept in a simple and engaging manner, making it a must-watch for anyone interested in data analysis and interpretation.
How to find Q1, Q2, Q3, and IQR
Seeking clarity on how to find q1? Look no further! Our comprehensive video tutorial simplifies the process of finding the first quartile in statistics. Whether you\'re a student or a professional, this step-by-step guide will equip you with the knowledge and skills to calculate q1 accurately, helping you excel in data analysis and make informed decisions.
What is the significance of Quartile 1 in statistical analysis?
Quartile 1 (Q1) is an important concept in statistical analysis as it helps divide a data set into four equal parts. It is the value that separates the lower 25% of the data from the upper 75%. In other words, it marks the boundary between the lowest 25% of the data and the next 25%.
To find Q1, you first need to order the data from smallest to largest. Then, you calculate the median, which is the middle value of the dataset. If the dataset has an odd number of values, the median is simply the middle value. If the dataset has an even number of values, you calculate the median by taking the average of the two middle values.
Once you have the median, you divide the dataset into two halves: the lower half (including the median) and the upper half. Q1 is the median of the lower half. It represents the value below which 25% of the data falls.
The significance of Q1 lies in its ability to provide information about the spread and distribution of the data. By determining the value at the 25th percentile, it helps identify the lower range of values and assess the variability within the dataset. Q1 is commonly used in conjunction with Q3 (the third quartile) to define the interquartile range (IQR), which measures the spread of the central 50% of the data.
Furthermore, Q1 is used in various statistical calculations, such as calculating outliers and defining box plots. Additionally, it can be used to compare different datasets, assess the skewness or symmetry of the distribution, and identify potential differences or patterns within the data.
In summary, Quartile 1 (Q1) is a crucial statistical measure that helps split data into quartiles and provides valuable insights into the lower range and distribution of the dataset.
Can you explain the steps involved in finding Q1?
Sure! Here are the step-by-step instructions to find Q1 (Quartile 1):
Step 1: Arrange the data in ascending order.
Start by organizing your data points in ascending order from smallest to largest. This will help in determining the position of Q1 in the dataset.
Step 2: Find the position of Q1.
In order to find the position of Q1, you need to use the formula: (N+1)/4, where N represents the total number of data points in your dataset. This formula helps in determining the position of the data point that represents Q1.
Step 3: Determine the value of Q1.
After finding the position of Q1, you need to identify the corresponding data point. If the position of Q1 is a whole number, then the value of Q1 is the average of the data points in that position and the one just after it. If the position is a decimal, round it up to the nearest whole number to locate the position of Q1, and then find the average of the two data points that surround it.
Step 4: Interpret the result.
Once you have calculated the value of Q1, this represents the point where the first quartile falls in your dataset. Q1 divides your data into four equal parts, and it is the median of the lower half of your dataset.
By following these steps, you should be able to find Q1 for any given dataset.

_HOOK_
Is there a specific formula to calculate the lower quartile (Q1)?
Yes, there is a specific formula to calculate the lower quartile, also known as Q1. The formula is as follows:
Q1 = (N + 1) x (1/4)
To calculate Q1 using this formula, you would need to follow these steps:
1. First, determine the total number of data points in your dataset or sample, represented by the variable N.
2. Add 1 to the total number of data points, N, to account for the additional point needed in the formula.
3. Multiply the result from step 2 by 1/4, or 0.25.
4. The final result will give you the index position of the lower quartile in your dataset.
5. If the result is a whole number, then the lower quartile is the value at that index position. If the result is a decimal, you would typically round it down to the nearest whole number and consider the value at that index position as the lower quartile.
It\'s important to note that the above formula assumes that the dataset is sorted in ascending order. If the dataset is not sorted, you would need to first arrange the data in order before applying the formula.
Are there any alternative methods to find Q1 apart from the one mentioned in the search results?
Yes, there are alternative methods to find Q1 (the first quartile) apart from the ones mentioned in the search results. One commonly used method is the \"percentile method\".
Here is a step-by-step guide to calculate Q1 using the percentile method:
1. Arrange the data in ascending order.
2. Determine the position of Q1, which is equal to (N+1) multiplied by 0.25, where N is the total number of data points.
3. If the position of Q1 is an integer, the Q1 value is the data point at that position.
4. If the position of Q1 is not an integer, round it down to the nearest whole number. Let\'s call this rounded-down value \"a\" and the next higher whole number \"b\".
5. Q1 is then calculated using linear interpolation: Q1 = (value in position a) + (position of Q1 - a) * (value in position b - value in position a).
For example, if we have a dataset of {3, 6, 7, 8, 9, 10, 13, 15, 16, 20}, and N = 10:
1. Arranging the data in ascending order gives: {3, 6, 7, 8, 9, 10, 13, 15, 16, 20}.
2. Position of Q1 = (10 + 1) * 0.25 = 2.75.
3. The position of Q1 is not an integer, so we round it down to 2.
4. Q1 = 7 + (2.75 - 2) * (8 - 7) = 7 + 0.75 = 7.75.
Therefore, the Q1 value in this dataset is 7.75.
It\'s important to note that there might be slight variations in the formula or steps used by different sources or statistical software, but the concept remains the same. The percentile method provides an alternative approach to finding Q1 and is commonly used in statistical analysis.
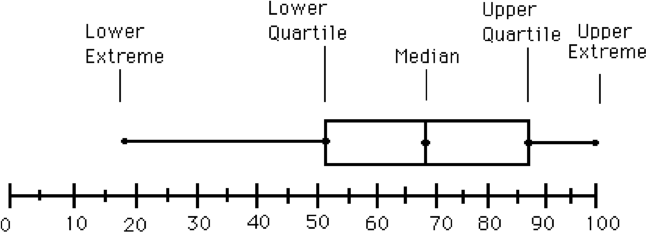
How does the value of Q1 help in understanding a data set or distribution?
The value of Q1, also known as the lower quartile, helps in understanding a data set or distribution by providing information about the spread of the lower 25% of the data. To calculate Q1, first arrange the data points in ascending order. Then, find the median of the lower half of the data set.
In a box plot, Q1 represents the left-hand edge of the \"box\" or the lower boundary of the interquartile range (IQR). The IQR is a measure of the spread or dispersion of the middle 50% of the data. Q1 helps us understand how the data is distributed within the lower 25% range.
If Q1 is closer to the minimum value, it suggests that the lower portion of the data is concentrated towards the minimum value, indicating a skewness towards the left side. On the other hand, if Q1 is closer to the median, it suggests a more balanced or symmetric distribution.
Q1 also helps identify potential outliers or extreme values in the lower end of the data set. Points that fall below a certain threshold below Q1 may be considered outliers. These outliers can provide valuable insights into the characteristics of the data set or indicate potential anomalies or exceptions in the data.
In summary, Q1 helps us understand the spread and distribution of the lower portion of a data set, provides insights into the skewness or symmetry of the distribution, and can identify potential outliers or extreme values.
Finding the Median, Lower Quartile, and Upper Quartile
Curious about the Median, the powerful tool used to represent the middle value of a dataset? Dive into our captivating video that demystifies the Median, revealing its significance in understanding distribution and central tendency. With clear explanations and real-life examples, this video is a valuable resource for anyone eager to enhance their statistical know-how.
Quartile for ungrouped data
Take a deep dive into the realm of ungrouped data with our enlightening video. Catering to both beginners and advanced learners, we explore the intricacies of working with ungrouped data, equipping you with the knowledge and techniques to analyze and interpret raw datasets. Uncover the untapped potential of ungrouped data in our captivating video.
Are there any limitations or assumptions while using Q1 for analysis?
When using Q1 (Quartile 1) for analysis, there are a few limitations and assumptions to consider:
1. Data Distribution: Q1 assumes that the data follows a specific distribution, specifically, it assumes that the data is symmetrical or nearly symmetrical. If the data is heavily skewed or has outliers, Q1 may not accurately represent the lower quartile.
2. Sample Size: The accuracy of Q1 is influenced by the size of the sample. Smaller sample sizes may lead to less reliable estimates of Q1, especially if the data is not evenly distributed.
3. Data Types: Q1 is typically used for analyzing continuous numerical data. It may not be applicable or meaningful for analyzing categorical or ordinal data.
4. Assumption of Ordinality: Calculating Q1 assumes that the data can be ranked in order of magnitude. This assumption may not hold if the data is nominal or lacks a natural ordering.
5. Variability: Q1 provides a summary measure of the lower 25% of the data, but it does not provide information about how the data is spread within this range. Variability within Q1 can vary widely, and it is important to consider other measures such as the Interquartile Range (IQR) or standard deviation to understand the spread of data.
Overall, while Q1 is a commonly used statistic for analyzing data, it is important to be aware of these limitations and assumptions and consider them in conjunction with other statistical measures and the specific context of the analysis.
READ MORE:
Can you provide examples or practical scenarios where finding Q1 is important and useful?
Finding Q1 (the first quartile) is important and useful in a variety of scenarios. Here are a few examples:
1. Descriptive Statistics: In data analysis, finding the quartiles is essential to gain a better understanding of the spread and distribution of a dataset. Q1 represents the 25th percentile, which means that 25% of the data falls below this value. It provides valuable information about the lower end of the distribution and helps in characterizing the data.
2. Boxplots: Boxplots are graphical representations of the distribution of data. They often display the quartiles, including Q1, as reference lines in the plot. Identifying Q1 in a boxplot helps to gauge the spread and skewness of the data and identify outliers if present.
3. Interquartile Range (IQR): The IQR, which is the range between Q1 and Q3 (the third quartile), is a measure of variability that is less sensitive to outliers than the overall range. It is frequently used to identify data points that may be considered as outliers using the 1.5*IQR rule. Q1 is a crucial component in calculating the IQR, making it necessary for this analysis.
4. Statistical Tests: Q1 is often used in statistical tests, such as the Mann-Whitney U test or Kruskal-Wallis test, to compare medians or distributions between groups. These tests rely on the calculation and comparison of quartiles, including Q1, to determine significant differences.
5. Data Partitioning: In decision-making or data classification tasks, Q1 can be utilized to divide the dataset into quartiles or percentile-based groups. This can help identify sub-groups with varying characteristics or target specific segments for further analysis or action.
Overall, finding Q1 is important in understanding the distribution, assessing variability, identifying outliers, comparing groups, and making informed decisions based on the data\'s characteristics. It is a fundamental statistic that provides valuable insights into the lower portion of a dataset.
_HOOK_